

近日,我院张守建课题组的论文“Vid-LLM: A Compact Video-based 3D Multimodal LLM with Reconstruction–Reasoning Synergy”被国际表征学习大会(International Conference on Learning Representations,ICLR)录用为口头报告论文。我院硕士研究生陈海吉尔和博士后徐博为论文共同第一作者,张守建为通讯作者,参与研究的还有硕士研究生刘皓泽、林嘉轩以及深圳大学王景荣博士。ICLR是人工智能与深度学习领域最具影响力的国际顶级会议之一,ICLR 2026有效投稿约为20000篇,口头报告论文录用率仅为1.1%。
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)在二维视觉-语言推理任务中取得了显著进展。然而,将其能力拓展到三维场景理解仍面临重大挑战。现有3D多模态大模型普遍依赖点云、深度图或外部三维重建结果,系统复杂、计算开销大,严重限制了模型的可扩展性和实际部署能力。
针对上述问题,论文提出了一种基于视频输入的三维多模态大模型框架——Vid-LLM。该方法仅使用单目视频作为输入,即可同时完成三维场景重建与三维视觉语言推理任务,实现了从“视频到三维理解”的端到端建模。模型设计了一种跨任务适配模块(Cross-Task Adapter, CTA),通过可学习的桥接标记(Bridge Tokens)在几何重建分支与语义推理分支之间建立结构化对齐机制,使几何信息与语言语义实现深度融合与协同优化。
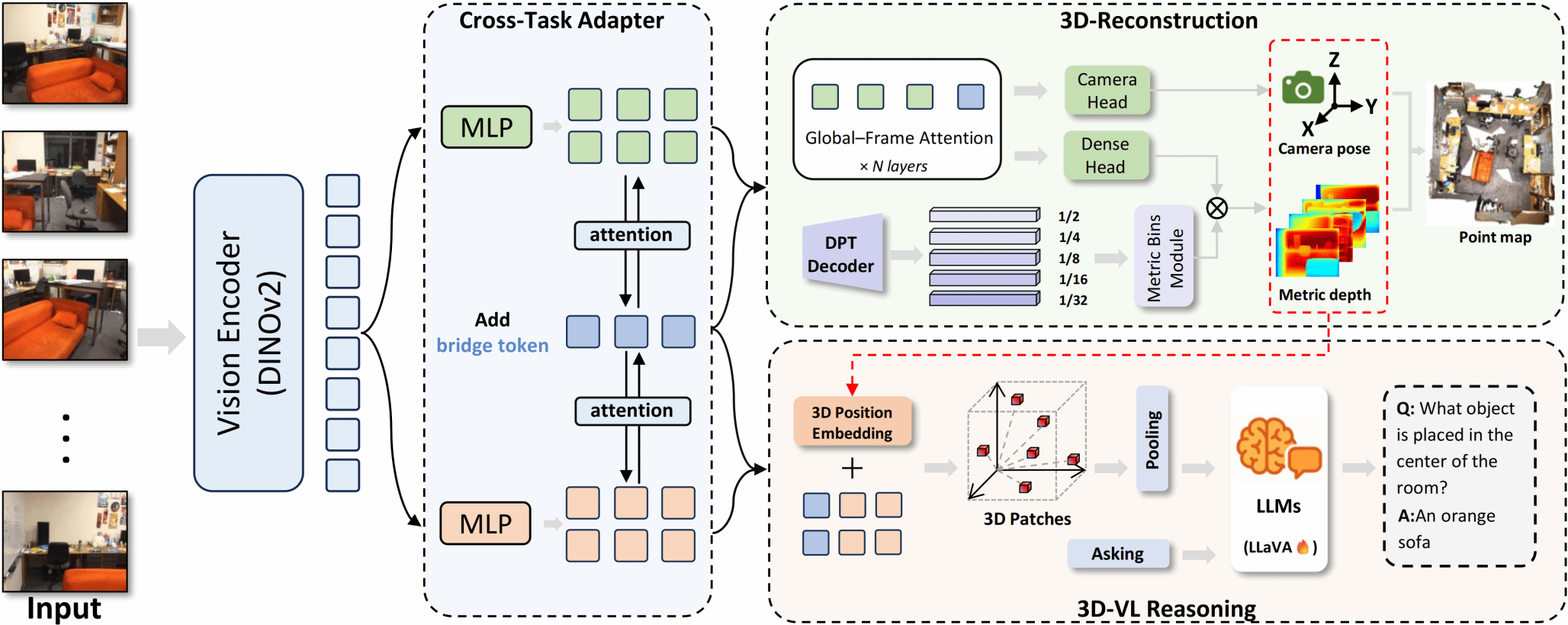
图1 Vid-LLM整体框架结构示意图
实验结果表明,在ScanQA、SQA3D、Scan2Cap、ScanRefer、Nr3D、Sr3D等多个主流三维视觉语言基准数据集上,Vid-LLM在仅使用视频输入的情况下取得了优于现有视频方法的性能表现,并在多个任务上达到或接近依赖显式三维输入模型的水平。同时,在联合重建与推理任务中,该方法在精度与推理效率方面均优于现有端到端框架。
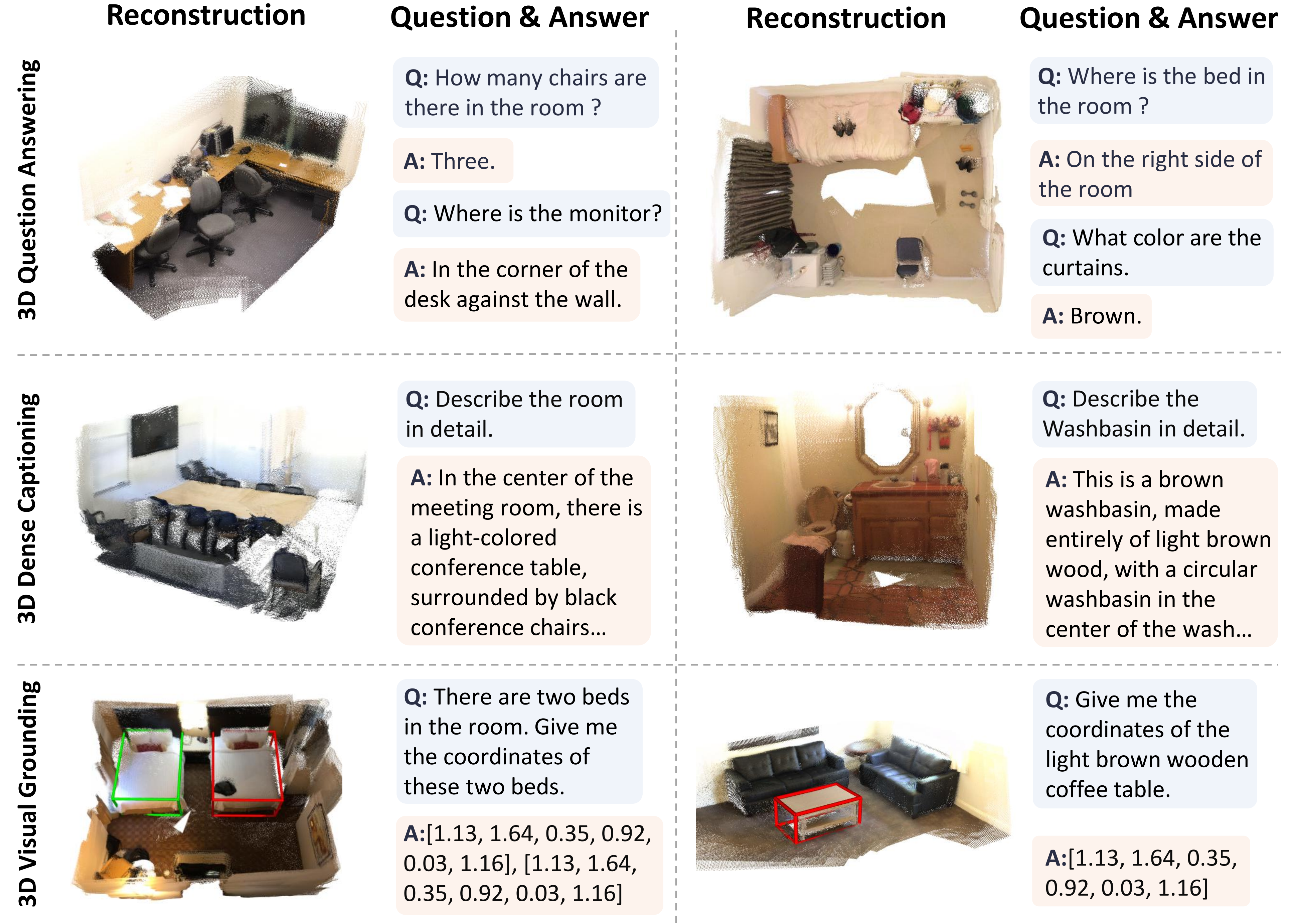
图2 三维视觉定位与推理可视化结果

图3 3D Grounding任务定性结果图
该研究突破了传统3D多模态模型对显式三维数据的依赖,实现了几何重建与语义推理的深度协同,为视频驱动的三维智能理解提供了一种高效、可部署的新范式,对具身智能、机器人感知与空间智能建模具有重要意义。
论文链接:https://arxiv.org/abs/2509.24385
图文:张守建
审核:金涛勇 胡俊英